Kundenservice automatisieren mit einem digitalen Support-Mitarbeiter.
Kundenservice automatisieren heißt nicht, jedes Ticket ungeprüft von KI beantworten zu lassen. Oft ist der bessere Start: Anfrage lesen, Kontext suchen, Antwortentwurf erstellen, Menschen entscheiden lassen.
Ein digitaler Support-Mitarbeiter entlastet euer Team bei Recherche, FAQ-Fällen und Vorbereitung, ohne heikle Antworten, Sonderfälle oder Kundendaten aus der Kontrolle zu geben.
Kundenservice automatisieren beginnt vor der Antwort.
Viel Zeit geht verloren, bevor eine Antwort geschrieben wird: alte Tickets suchen, Kundendaten prüfen, interne Regeln lesen, Kontext aus mehreren Systemen zusammensuchen.
- 01
Tickets lesen und einordnen
- 02
Passenden Kontext aus Wissensquellen und Systemen suchen
- 03
Antwortentwürfe vorbereiten
- 04
FAQ-Fälle innerhalb klarer Grenzen automatisieren
- 05
Unklare Fälle mit Kontext eskalieren
- 06
Rechercheergebnisse für Menschen sichtbar machen
Kein Chatbot, der alles beantworten soll.
Chatbot-Antworten sind zu eng gedacht
Viele Support-Projekte starten mit der falschen Erwartung: Die KI soll sofort jede Anfrage selbst beantworten. Das wirkt in einer Demo einfach und wird im Betrieb schnell riskant.
Ein digitaler Support-Mitarbeiter kann zuerst als Recherche- und Draft-System starten. Wenn bestimmte Anfragearten stabil funktionieren, wird mehr automatisiert. Alles andere bleibt beim Menschen.
Gute Automatisierung hat klare Grenzen
Wenn Fragen klar wiederkehren, kann ein digitaler Support-Mitarbeiter mehr übernehmen: FAQ erkennen, passende Antwort geben und alles außerhalb des Scopes eskalieren.
Das funktioniert besonders gut, wenn ihr saubere Wissensquellen habt und klar definiert ist, welche Antworten automatisiert werden dürfen.
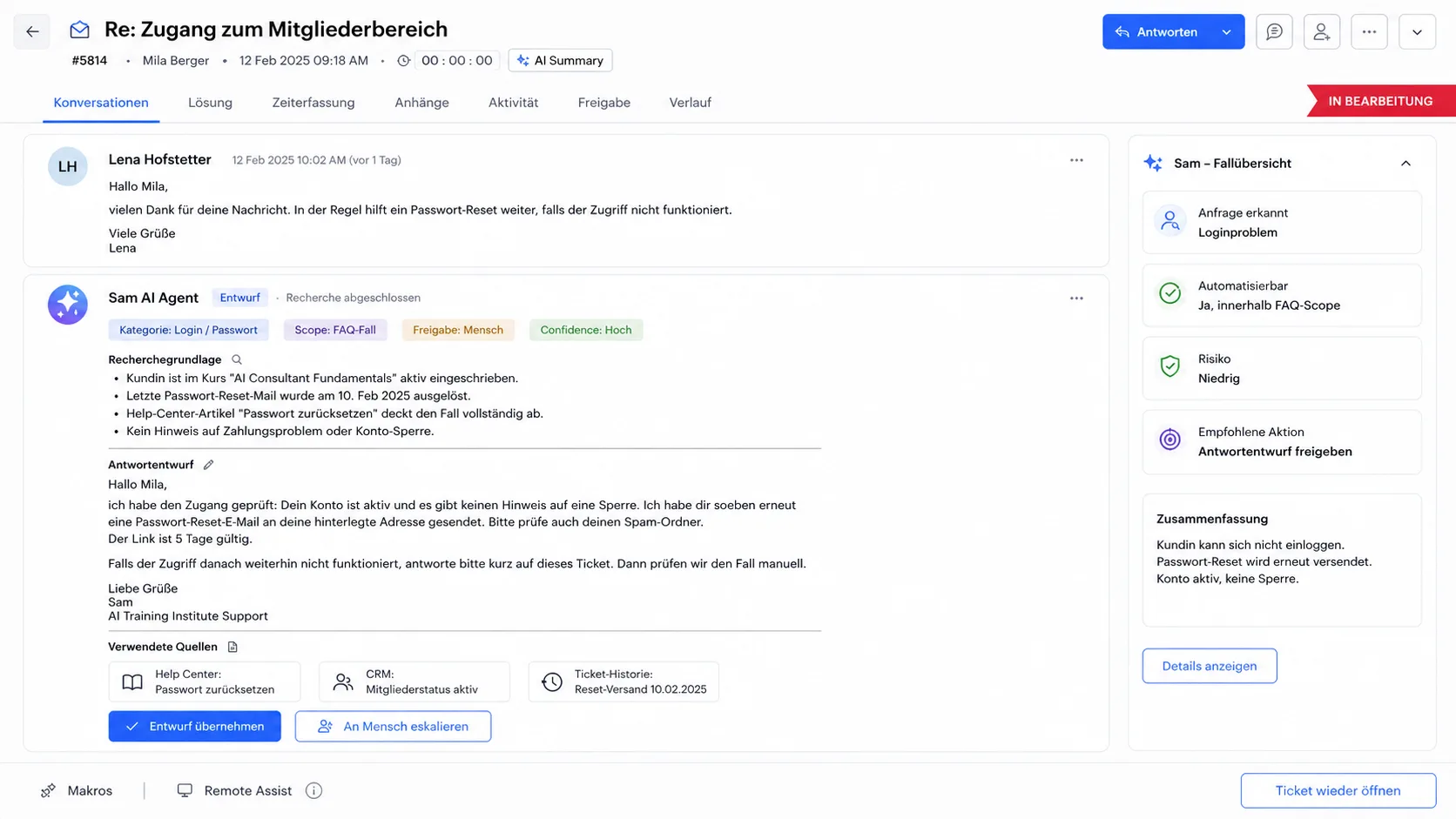
Sam erstellt Antwortentwürfe mit Rechercheergebnis.
Sam arbeitet in einem Ticketsystem. Sam liest eine Anfrage, sucht den benötigten Kontext in mehreren Systemen und erstellt einen Antwortentwurf. Dazu liefert Sam das Rechercheergebnis, damit ein Mensch die Antwort prüfen und senden kann.
- 01 · Eingang
Ein Ticket kommt im Support-System an.
Quelle und Kategorie sind in der Pipeline definiert.
- 02 · Lesen
Sam liest die Anfrage und erkennt, welche Informationen fehlen.
Was wird gefragt, was ist Kontext, was ist offen?
- 03 · Recherche
Sam sucht den passenden Kontext in den relevanten Systemen.
Wissensbasis, CRM, Vertrags- und Bestelldaten, alte Tickets.
- 04 · Entwurf
Sam erstellt einen Antwortentwurf mit Recherchegrundlage.
Damit nachvollziehbar bleibt, woher die Info stammt.
- 05 · Freigabe
Ein Mensch prüft, passt an und sendet.
Bei FAQ-Fällen kann die Freigabe später automatisiert werden.
Sam ist in diesem Setup kein Autopilot. Sam nimmt dem Team vor allem die Sucharbeit ab.
Häufige Fragen.
Kann KI den Kundenservice automatisieren?
Ja, aber nicht sinnvoll als offener Autopilot. Ein guter Start ist oft ein Entwurf mit Rechercheergebnis. Das Team prüft und sendet die Antwort. Mehr Automatisierung kommt erst dort dazu, wo Anfrageart, Wissensquelle und Eskalation klar sind.
Welche Kundenservice-Anfragen eignen sich für Automatisierung?
Gut geeignet sind wiederkehrende Fragen, klare FAQ-Fälle, Anfragen mit ähnlicher Struktur und Tickets, bei denen vor allem Kontext aus bestehenden Systemen gesucht werden muss.
Kann ein Ticket-System angebunden werden?
Viele Ticket-Systeme können angebunden werden, wenn Schnittstellen, Datenzugriff und Rechte passen. Zendesk und Zoho Desk haben wir in aktuellen Kundenprojekten bereits angebunden.
Wie werden falsche Antworten verhindert?
Durch begrenzte Aufgaben, geprüfte Wissensquellen, Antwortentwürfe statt Autopilot, Eskalationsregeln, Audit Logs und menschliche Freigabe bei Risiko.
Wann wird an Menschen eskaliert?
Wenn der Fall außerhalb des definierten Scopes liegt, Daten fehlen, die Antwort unsicher ist oder eine Entscheidung menschliche Verantwortung braucht.
Was passiert mit Kundendaten?
Kundendaten werden nicht für das Training fremder LLMs verwendet. Backend und eingesetzte LLMs laufen in der EU. Die konkrete Datenverarbeitung wird pro Setup dokumentiert.
Ihr wollt wissen, ob sich euer Kundenservice kontrolliert automatisieren lässt?
Über einen Support-Piloten sprechenYuno stellt euch vier kurze Fragen zu Anfragevolumen, Wissensquellen, Risikofällen und Freigabe. Danach ist klarer, ob ein Support-Pilot sinnvoll ist.